How Aggregated Viewer Feedback Reshapes Discovery Paths for Overlooked Titles Across Ad-Supported Platforms

Ad-supported streaming services have integrated viewer data streams into their recommendation engines, and this shift has altered how lesser-known films and series reach audiences. Platforms collect completion rates, search queries, and explicit ratings to form aggregated profiles that influence visibility algorithms, while data from May 2026 shows continued expansion of these systems across multiple services.
Mechanics of Aggregated Feedback Collection
Viewers generate signals through everyday interactions such as pausing, rewinding, or finishing content without skipping ads, and these actions feed into centralized databases that platforms process daily. Aggregated datasets combine anonymous metrics from thousands of users rather than individual histories, which allows systems to identify patterns like rising interest in specific genres or regions. Researchers at academic institutions have documented how such pooling reduces noise from outliers and highlights consistent preferences that traditional metadata alone overlook.
Algorithm Adjustments and Path Creation
Once feedback accumulates, platforms adjust ranking weights so that titles with steady engagement climb higher in browse rows and personalized carousels, and this process creates new discovery routes for productions that previously remained buried under popular releases. Completion percentage often carries heavier influence than star ratings alone, because sustained watch time signals genuine interest rather than casual clicks. Industry reports indicate that services refresh their recommendation models weekly, incorporating fresh aggregates to keep pathways responsive to emerging viewer clusters.
External data sources supplement internal logs when platforms partner with measurement firms, yet the core remains viewer-driven signals that surface during peak viewing hours. Observers note that overlooked titles gain traction faster when feedback clusters around particular demographics or time slots, prompting algorithmic promotion without requiring marketing budgets.
Case Examples from Platform Operations
One service documented a low-budget science-fiction film that moved from page ten of search results to featured placement after aggregated watch-time data exceeded thresholds set for similar entries. Another platform recorded increased trailer views for an independent drama once completion metrics from initial viewers triggered broader distribution in related playlists. These shifts occur because systems prioritize titles that retain attention across repeated impressions rather than relying solely on initial launch performance.
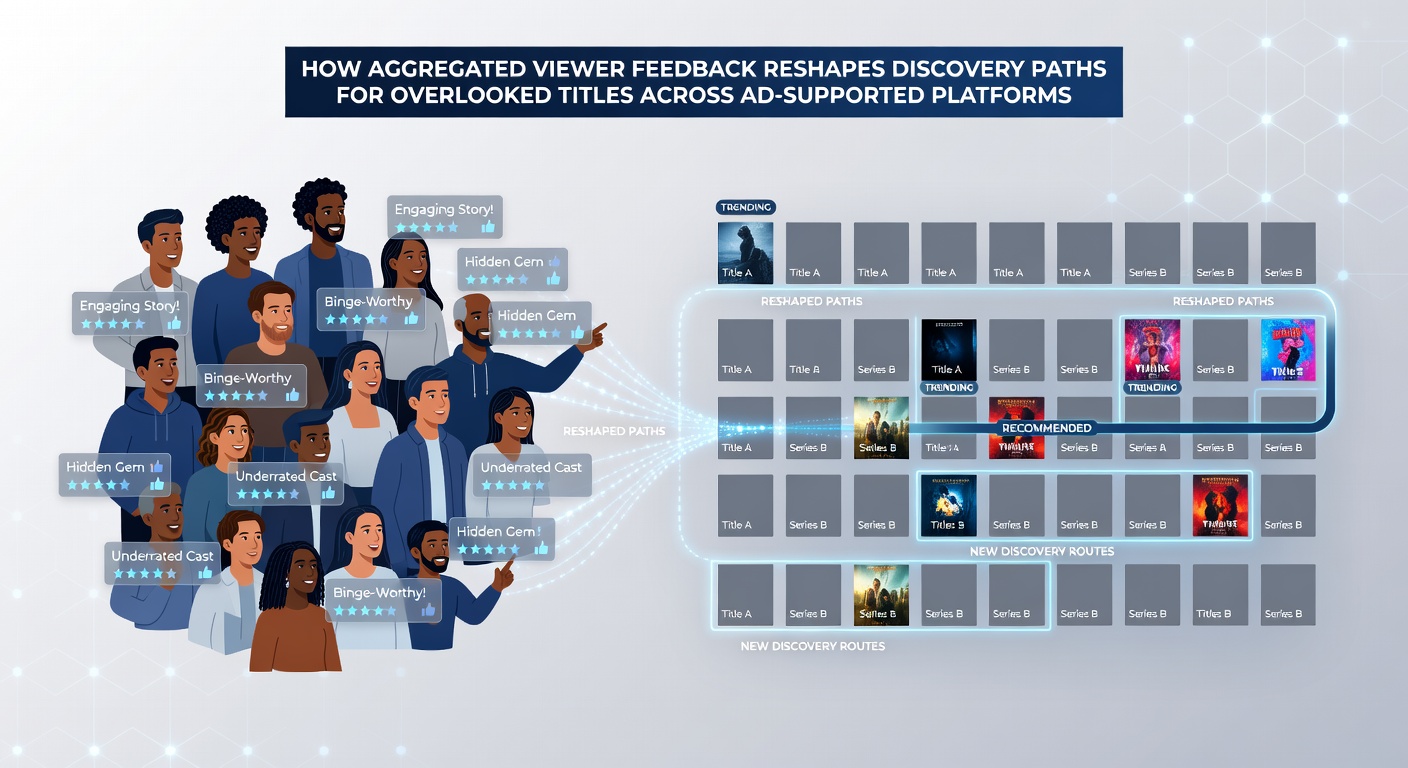
Studies from university research groups reveal that feedback loops operate continuously, and titles can re-enter prominence months after release if later viewer cohorts discover them through cross-promotions. Data from these analyses shows measurable lifts in ad impressions once overlooked content reaches wider rotation, because sustained plays extend session lengths and generate additional revenue opportunities for the platform operators.
Regional Variations and Regulatory Context
Services operating in different markets adapt feedback models to local regulations, and Canadian authorities have examined how data aggregation practices align with privacy standards while still enabling discovery features. European frameworks similarly guide the balance between user consent and algorithmic transparency, leading some platforms to publish summaries of how aggregated signals influence placement decisions. These approaches vary by jurisdiction yet share the common outcome of expanding reach for titles that accumulate positive engagement patterns.
What's interesting here is the way feedback aggregation creates self-reinforcing cycles where initial viewer interest snowballs into broader exposure, and this dynamic particularly benefits independent productions that lack traditional promotional support. Platforms report that such cycles have increased catalog utilization rates, allowing smaller titles to contribute meaningfully to overall viewing hours without displacing established hits.
Future Trajectories Based on Current Trends
Continued refinement of feedback systems appears likely as machine-learning models incorporate additional signals such as social mentions and search volume trends. Reports from organizations tracking digital media consumption project further integration of these elements into discovery paths by late 2026, which would potentially accelerate promotion of niche content across ad-supported environments. The result remains a more dynamic catalog experience where viewer-driven data continuously updates visibility for productions that might otherwise stay hidden.
Conclusion
Aggregated viewer feedback has become a central driver in how ad-supported platforms surface overlooked titles, reshaping discovery through data-informed ranking and placement adjustments. Evidence from operational records and independent analyses confirms that these mechanisms expand audience access while supporting platform economics through extended engagement. As systems evolve, the pathways available to lesser-known content will likely grow more responsive to collective viewer behavior across regions and device types.